mongopipe-core


![]()



Intro
How to store MongoDB aggregation pipelines in the database and run them?.
A MongoDB aggregation pipeline is a JSON document, so store it in the database.

Why storing queries in DB?
- Runtime configurability
- Hardcoding avoided (no more one code page long native queries together with the code)
- Pipelines are documents thus a structured format.
- Avoid native queries with ‘DB agnostic’ libraries.
Use cases:
- Runtime changes. Want to be able to change underlying queries/rules and avoid the use of an abstraction layer(e.g. query builder) that might limit the full potential of the database.
E.g.: Configuring DB alerts/rules for a risk detection solution. - Urgent changes by DBAs/admins are needed without waiting for patches/releases containing changed queries.
Thus the system can adapt quickly and the admin/dba doing them would not need coding or devops skills. - UI widgets data source customization. An admin can easily customize a chart, a report or a widget data source by just editing the backing pipeline via a REST api.
For example a combo box currently displaying a limit of 5 countries stored in the DB, may need to display 10 countries filtered on different conditions based on the client(multitenant app). By keeping the pipeline in the database, an admin user can easily change it to display 10 countries or the conditions.
Getting started in 3 easy steps
1. Configuration
With Spring:
Maven dependency:
<dependency>
<groupId>org.mongopipe</groupId>
<artifactId>mongopipe-spring</artifactId>
<version>1.0.0</version> <!-- Get latest from Maven Central or https://mvnrepository.com/artifact/org.mongopipe/mongopipe-spring -->
</dependency>
Add 2 beans required for configuration and autostarting.
@Bean
public MongoPipeConfig getMongoPipeConfig() {
return MongoPipeConfig.builder()
.uri("mongodb://...")
.databaseName("database name")
//.mongoClient(optionallyForCustomConnection) // e.g. for TLS setup
.build();
}
@Bean
public MongoPipeStarter getMongoPipeStarter(MongoPipeConfig mongoPipeConfig) {
return new MongoPipeStarter(mongoPipeConfig);
}
Without Spring:
<dependency>
<groupId>org.mongopipe</groupId>
<artifactId>mongopipe-core</artifactId>
<version>1.0.1</version> <!-- Get latest from Maven Central or https://mvnrepository.com/artifact/org.mongopipe/mongopipe-core -->
</dependency>
Manually register config.
Stores.registerConfig(MongoPipeConfig.builder()
.uri("<mongo uri>")
.databaseName("<database name>")
//.mongoClient(optionallyForCustomConnection) // e.g. for TLS setup
.build());
2. Create JSON pipelines
Create a JSON/BSON resource file myFirstPipeline.json that will be automatically migrated(inserted) in the database collection pipeline_store at startup.
{
"id": "matchingPizzas",
"collection": "pizzas",
"pipeline": [
{
$match: { size: "${pizzaSize}" }
},
{
$sort : { name : 1 }
}
]
}
- Store the above json file in your source code, under
src/main/resources/pipelines(configurable viaMongoPipeConfig#migrationConfig#pipelinesPath). - On Migration (at process startup time) all the pipelines from that folder will be created(if new) or updated(if changed)
in the database collection
pipeline_store. Any future changes to the pipeline files will be detected and reflected in the database during startup migration run check.
If you are not using Spring and mongopipe-spring dependency you need to manually call the migration on every process start usingPipelines.startMigration(). - For a list of all possible fields that you can use check the model class
Pipeline javadoc.
3. Run pipelines
Create just an interface with @PipelineRun annotations. This way you bind code (interface methods) with pipelines stored in DB.
@Store
public interface MyRestaurant {
@PipelineRun("matchingPizzas") // the db pipeline id, if missing is defaulted to method name.
Stream<Pizza> getMatchingPizzas(String pizzaSize);
}
// With Spring ("mongopipe-spring" dependency):
@Autowired
MyRestaurant myRestaurant;
...
myRestaurant.getMatchingPizzas("MEDIUM");
// Without Spring:
Stores.from(MyRestaurant.class)
.getMatchingPizzas("MEDIUM");
NOTE:
- Internally a proxy store delegator is created for each @Store annotated interface and for each @PipelineRun annotation will execute the corresponding DB stored pipeline.
- The
@Storeclass annotation is mandatory. The@PipelineRunannotation is optional and if missing the pipeline id will be defaulted to the method name. - For generic running usages like the ones in the Intro section, meaning no need for pipeline stores(
@Storeannotated), you can use thePipelines.getRunner().runmethod. More here: Generic creation and running You can use this behind a REST api to generically create and run pipelines.
You only need the pipeline document to exist in the database collection (pipeline_store) or to be provided at runtime. - The parameters actual values provided are expected to be in the same order as in the pipeline template. For clearer identification
annotate using
@Paramthe method parameter and provide the template parameter name:
List<Pizza> getMatchingPizzas(@Param("pizzaSize") String pizzaSize). - As secondary functionality, it supports generation of a CRUD operation just from the method naming similar with Spring Data. See CRUD stores
More on pipeline files
- Pipeline files/sources are saved (via migration process) in the
pipeline_storecollection: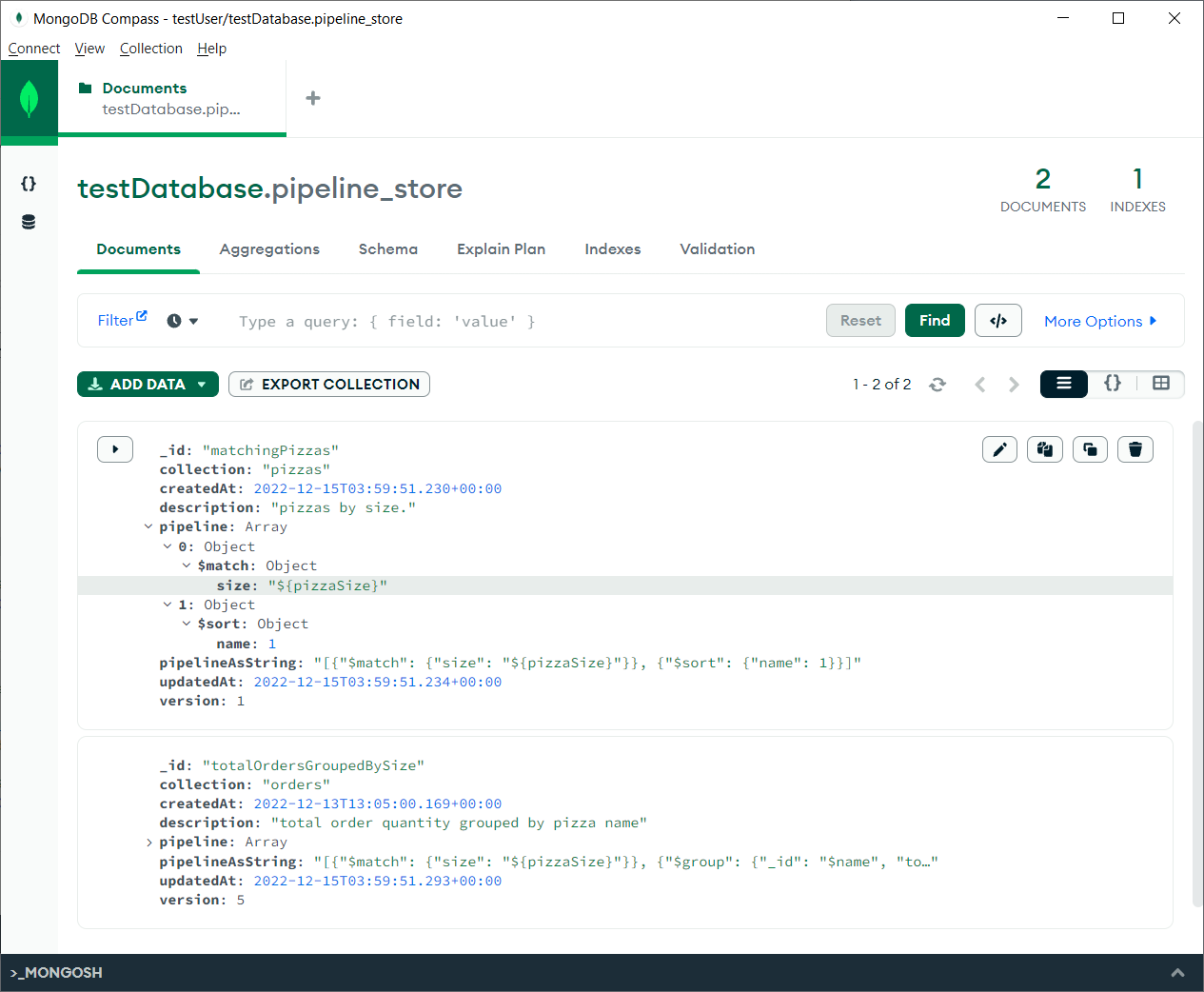
- Once migrated in the database, pipelines can be independently updated/created at runtime using the PipelineStore CRUD API.
Future file updates to the pipeline file will be promoted to DB via automatic migration on startup. - The pipelines can be also manually created/updated using the dynamic way.
- The json pipeline file although static, it is consumed by the migration utility at process startup and then seeded in the database. After reaching the database it can then be independently updated at runtime via the
PipelineStoreAPI.
Future modifications to the seed file will be automatically propagated in the database by the migration process on the next process startup/restart. More on Migration. - The parameters form is
"${paramName}".
Parameters inside the pipeline template must be strings (e.g."..": "${paramName}") in order to be valid JSON. On pipeline run the actual parameters values can be of any type including complex types: lists, maps, pojos as long as it can be converted to a JSON/BSON type.
For example on pipeline running if the actual parameter value is an integer (e.g. 10) the string value:
"x": "${paramName}",will become an integer value:
"x": 10, - The pipeline files can have .json or .bson file extension. It is recommended to use .bson extension when the pipeline contains BSON types that are not standard JSON.
Dynamic creation and running with criterias
Sometimes instead of using an interface to define the pipeline run methods you can instead manually both create and run a pipeline.
This is useful if you do not want to create @PipelineRun annotated methods for every pipeline run.
By using PipelineRunner you can run any pipeline.
By using PipelineStore and criterias APIs, subparts of the pipeline can be constructed dynamically.
Examples:
// Use PipelineStore for any CRUD operations on pipelines.
PipelineStore pipelineStore = Pipelines.getStore();
PipelineRunner pipelineRunner = Pipelines.getRunner();
// ********
// You can create a pipeline dynamically or from criterias in several ways:
// ********
// ********
// 1. Using Mongo BSON criterias API, static imports are from Mongo driver API class: com.mongodb.client.model.Aggregates/Filters/Sorts.
// Criterias examples: https://www.mongodb.com/docs/drivers/java/sync/v4.7/fundamentals/crud/read-operations/
// ********
// Pipeline stages one by one.
List<Bson> pipelineBson = Arrays.asList(
// Static imports from com.mongodb.client.model.Aggregates/Filters/Sorts
match(and(eq("size", "${size}"), eq("available", "${available}"))),
sort(descending("price")),
limit(3)
);
Pipeline dynamicPipeline = Pipeline.builder()
.id("dynamicPipeline")
.pipeline(pipelineBson)
.collection("testCollection")
.build();
pipelineStore.create(dynamicPipeline);
List<Pizza> pizzas = pipelineRunner.run("matchingPizzas", Pizza.class, Map.of("size", "medium", "available", true)) // Returns a stream
.collect(Collectors.toList());
// ********
// 2. Replacing entire sections of a minimal static pipeline by making them variables.
// As parameter value provide Java types corresponding to JSON (e.g. maps, arrays) or POJO classes with getters and setters.
// ********
// This will normally come from an outside source, provided by an admin/DBA.
String jsonString = "{ \"_id\": \"dynamicPipeline\", \"version\": 1, \"collection\": \"testCollection\", \"pipelineAsString\":\"[" +
"{\\\"$match\\\": {\\\"$and\\\": [{\\\"size\\\": \\\"${size}\\\"}, {\\\"available\\\": \\\"${available}\\\"}]}}," +
"{\\\"$sort\\\": \\\"${sortMap}\\\" }," +
"{\\\"$limit\\\": 3}]\" }";
Pipeline pipeline = BsonUtil.toPojo(jsonString, Pipeline.class);
pipelineStore.create(pipeline);
// 3rd param is a map/object by itself and can be arbitrarily deep. Also an entire stage can be provided.
// NOTE: Here we use a Map type as parameter value for 'sortMap' parameter. But any POJO class of your choice can be used
// and needs just getters and setters in order to be convertible to JSON (BsonUtil#toBsonValue beeing called).
List<Pizza> pizzas = pipelineRunner.runAndList(pipeline.getId(), Pizza.class, Maps.of("size", "medium", "available", true,
"sortMap", Maps.of("price", -1, "name", 1)));
// ********
// 3. From plain JSON/BSON String. Thus entire pipeline can be provided by an admin/DBA.
// ********
String pipelineStages = BsonUtil.escapeJsonFieldValue("[" +
"{\"$match\": {\"$and\": [{\"size\": \"${size}\"}, {\"available\": \"${available}\"}]}}," +
"{\"$sort\": {\"price\": -1}}," +
"{\"$limit\": 3}" +
"]");
String jsonString = "{ \"_id\": \"dynamicPipeline\", \"version\": 1, \"collection\": \"testCollection\"," +
" \"pipelineAsString\":\"" + pipelineStages + "\" }";
Pipeline pipeline = BsonUtil.toPojo(jsonString, Pipeline.class);
pipelineStore.create(pipeline);
List<Pizza> pizzas = pipelineRunner.run("matchingPizzas", Pizza.class, Map.of("size", "medium", "available", true))
.collect(Collectors.toList());
// ********
// 4. Dynamically create/update pipeline using one of the above ways. Then call dedicated method (@PipelineRun annotated).
// ********
// ... create/update Pipeline manually using one of the above methods.
pipelineStore.update(pipeline);
...
myRestaurant.getMatchingPizzas("MEDIUM");
NOTE:
- Both PipelineStore and PipelineRunner can be easily called from an API like REST. Example REST api from the ‘Examples’ repo.
- From the solutions above you should probably consider using 1 (MongoDB criterias API) or 2 (your own criteria API) or a combination of both.
- Store obtained via
Pipelines.getStore()can be used also to create, update and delete pipelines. - The pipelines are cached so when running a pipeline that cache is hit first. The cache is automatically updated when you modify the pipelines via the API.
- Once a pipeline is modified (with
PipelineStore) you can continue to use both@PipelineRunannotated methods andPipelineRunnerto run it. - As parameter values you can use not just plain Java types (int, long, float, strings, Map, List) but also any POJO class of your choice.
The POJO class needs just getters and setters in order to be convertible to JSON (
BsonUtil#toBsonValuebeeing called on it).
Migration
The migration will be started automatically on process start if using Spring framework (mongopipe-spring dependency required) or manually by invoking:
Pipelines.startMigration();
How pipeline changes are detected:
- Fast check: A fast global checksum is created from the
lastModifiedTimeof all incoming pipelines and this checksum is compared with the existing one in the db (saved in the previous run). - Deep check: If the global checksum based on timestamp matches then skip migration. Else iterate on each incoming pipeline, create a checksum based on content, compare it with the existing checksum in db(saved in a previous run) and create/update db pipeline if content checksums do not match. Also save latest checksums at the end.
The prior value of an updated pipeline will be saved in thepipeline_store_historycollection for backup purposes. This is configurable.
Default pipeline migration golden source issrc/main/resources/pipelines(configurable in step 1 configuration viaMongoPipeConfig#migrationConfig#pipelinesPath) so store your pipelines json files in that folder.
The pipelines golden source is also configurable in case you want to keep track of the original pipelines within a database instead of a resources folder:RunContextProvider.getContext().setPipelineMigrationSource(yourDbPipelineSource);Still remember that the final destination of the pipelines (after migration), is the
pipeline_storedb collection where you can update them any time at runtime.
A pipeline that was modified at runtime (in the pipeline store) but did not had the golden source updated will not be overwritten on migration. It will only be overwritten when the corresponding pipeline is updated in the golden source.
CRUD stores
NOTE: This is subject to change.
A @Store annotated interface can support both @PipelineRun methods and also CRUD methods by naming convention.
For CRUD methods by naming convention (similar with Spring Data) the method signature must match one of the methods from org.mongopipe.core.store.CrudStore.
E.g.:
@Store(
items = {
@Item(type = Pizza.class, collection = "pizzas")
}
)
public interface PizzaRestaurant {
Pizza save(Pizza pizza);
Pizza findById(String id);
Iterable<Pizza> findAll();
Long count();
}
NOTE:
- The store(via the
@Storeannotation) decides where to put the items and not vice versa, meaning an item type class is almost storage agnostic. Thus, the annotation@Store#itemsfield acts as a database mapping definition recipe. Another benefit of this mapping definition is that it can be stored in db or in a file, referenced by id, or defaulted to all stores. - This feature is not yet mature, main feature is to manage and run pipelines.
More examples
Find more examples in samples repo.
Data update operations
For performing data updates on MondoDB documents there are several options:
- Without pipelines, you can use CRUD stores. Still has a limited set of operations.
- With pipelines, using update stages like for example the
$replaceRoot. - With pipelines, using dedicated commands like for example findOneAndUpdate which can be run by setting
Pipeline#commandOptions. The findOneAndUpdate allows also to insert the document if it does not exist.
Docs
Main documentation site: https://www.mongopipe.org
JavaDoc.
TODO
- Features requested by users. This is the most important.
- Use MongoDB ChangeStreams to automatically update the optional pipeline cache backing the pipeline store. This is for when pipelines are updated by another external process. Now a manual call is needed in case of external modifications: PipelineStore#refresh
- Documentation with Hugo.
Support and get in touch
![]()
![]() Contributions and suggestions are welcomed from everyone. If you have a bug/proposal just contact us directly or browse the open issues and create a new one.
Contributions and suggestions are welcomed from everyone. If you have a bug/proposal just contact us directly or browse the open issues and create a new one.
![]() We like direct discussions. Check email address on the github profile of the committers.
We like direct discussions. Check email address on the github profile of the committers.